フリーランスエンジニアをしているrevenue-hackです!
普段はGo言語でバックエンドを中心にやっています〜
今回はデータベースの特にRDBの仕組み(アーキテクチャ)についてざっくり理解して、なにかに役立てようぜ〜
というような内容になります。
記事執筆者:オザック
Web開発(バックエンド兼インフラ)を生業にしている、エンジニア歴9年以上のrevenue-hackです!
某有名R社で働き、副業も含めて個人事業主で関わってきたプロジェクトは20以上。
DDDやクリーンアーキテクチャ、AWS、RDBの設計、チューニングなどを教えたり、実装していたりします!
現在はフリーランスとして従事。
バックエンド、インフラに関する業務での相談事や個人開発の相談事など受けてます!
MENTAでバックエンドやAWSインフラ、RDBの設計、チューニングをサポート!
普段ゆる〜くアーキテクチャやデータベースのことなどを発信しています〜
筆者関連記事: バックエンドのやばい設計記事
目次
データベースの仕組み(アーキテクチャ)の記事の対象者
想定読者
- バックエンドエンジニアでなんとなく仕組み知っておきたい人
- データベースの仕組みを知ってインデックス貼ったりとかの勉強に役立てたい人
- 仕組みをざっくり知ってなんとなくデータベース語りたい人
向けです!
データベース(RDB)の仕組み(アーキテクチャ)は大体同じ
RDBといえば
- Oracle
- SQLServer
- MySQL
- Postgres
あたりが有名かと思います。
ポイント
ただRDBの細かい仕様や設計、命名は違いますが、基本的に全RDBは同じようなアーキテクチャになっています!
なので1つのRDBの仕組みを追えばおおよそRDBのアーキテクチャは理解できるようになっています。

SQLの処理の流れ
まずはアーキテクチャの前にSQLの流れをざっくりおさらい。
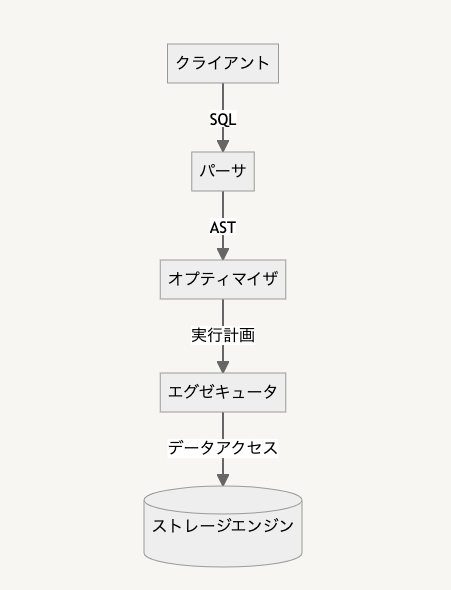
SQLの処理の流れ
簡単な流れ
- まずクライアントからSQLが投げられると、パーサーでSQLを解析してAST(抽象構文木)を生成する
- 生成した抽象構文木からオプティマイザが、事前に収集してあったデータを元に、複数通りの実行計画を作り、コストを定量化する
- その中からコストが一番低い実行計画を実行し、エグゼキュータがストレージエンジンにアクセスしてSQLの結果を出す
と言う流れになっています。
解析木の例
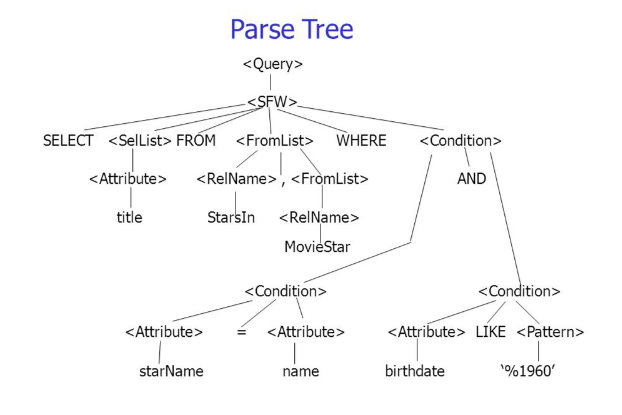
解析木の例
解析木のイメージはこんな感じ。
オプティマイザトレースの例
MySQLではjsonでSQLのオプティマイザトレースの結果が出せるようになっています。
実際それを出してみるとこんな感じになってます。
メモ
5.7以降だとちゃんとコストも表示されるので、SQLを調査したい人には良いです!
EXPLAIN FORMAT=JSON SELECT ...
explain時に`FORMAT=JSON`をつけるとOKです!
- {
- "query_block": {
- "select_id": 1,
- "cost_info": {
- "query_cost": "404995.39"
- },
- "nested_loop": [
- {
- "table": {
- "table_name": "l",
- "access_type": "ALL",
- "rows_examined_per_scan": 331143,
- "rows_produced_per_join": 331143,
- "filtered": "100.00",
- "cost_info": {
- "read_cost": "4141.79",
- "eval_cost": "33114.30",
- "prefix_cost": "37256.09",
- "data_read_per_join": "5M"
- },
- "used_columns": [
- "emp_no",
- "from_date",
- "to_date"
- ],
- "materialized_from_subquery": {
- "using_temporary_table": true,
- "dependent": false,
- "cacheable": true,
- "query_block": {
- "select_id": 3,
- "cost_info": {
- "query_cost": "33851.30"
- },
- "grouping_operation": {
- "using_filesort": false,
- "table": {
- "table_name": "dept_emp",
- "access_type": "index",
- "possible_keys": [
- "PRIMARY",
- "dept_no"
- ],
- "key": "PRIMARY",
- "used_key_parts": [
- "emp_no",
- "dept_no"
- ],
- "key_length": "20",
- "rows_examined_per_scan": 331143,
- "rows_produced_per_join": 331143,
- "filtered": "100.00",
- "cost_info": {
- "read_cost": "737.00",
- "eval_cost": "33114.30",
- "prefix_cost": "33851.30",
- "data_read_per_join": "10M"
- },
- "used_columns": [
- "emp_no",
- "dept_no",
- "from_date",
- "to_date"
- ]
- }
- }
- }
- }
- }
- },
- {
- "table": {
- "table_name": "d",
- "access_type": "ref",
- "possible_keys": [
- "PRIMARY"
- ],
- "key": "PRIMARY",
- "used_key_parts": [
- "emp_no"
- ],
- "key_length": "4",
- "ref": [
- "employees.l.emp_no"
- ],
- "rows_examined_per_scan": 1,
- "rows_produced_per_join": 16557,
- "filtered": "4.52",
- "cost_info": {
- "read_cost": "331143.00",
- "eval_cost": "1655.72",
- "prefix_cost": "404995.39",
- "data_read_per_join": "517K"
- },
- "used_columns": [
- "emp_no",
- "from_date",
- "to_date"
- ],
- "attached_condition": "((`employees`.`d`.`to_date` = `employees`.`l`.`to_date`) and (`employees`.`d`.`from_date` = `employees`.`l`.`from_date`))"
- }
- }
- ]
- }
- } |
選ばれた実行計画をexplainでみるとこんな感じ
+----+-------------+------------+------------+-------+-----------------+---------+---------+--------------------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+-----------------+---------+---------+--------------------+--------+----------+-------------+
| 1 | PRIMARY | <derived3> | NULL | ALL | NULL | NULL | NULL | NULL | 331143 | 100.00 | NULL |
| 1 | PRIMARY | d | NULL | ref | PRIMARY | PRIMARY | 4 | employees.l.emp_no | 1 | 4.52 | Using where |
| 3 | DERIVED | dept_emp | NULL | index | PRIMARY,dept_no | PRIMARY | 20 | NULL | 331143 | 100.00 | NULL |
+----+-------------+------------+------------+-------+-----------------+---------+---------+--------------------+--------+----------+-------------+
データベース(RDB)の仕組み(アーキテクチャ)について
なんとなーくSQLの処理の仕組みと流れがわかった所で、次は本題のデータベースのアーキテクチャについて説明していきます!
注意ポイント
※先に言っておくと、あくまでオーソドックスな流れを紹介するので、今回とは違うエッジケースの処理フローをたどることもあります!
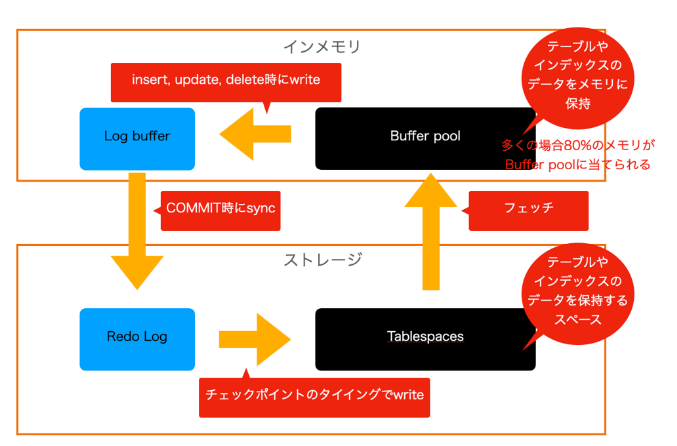
データベースのアーキテクチャ(仕組み)
| 名称 | 説明 | 領域 |
| ---- | ---- | ---- |
| Buffer pool | データのキャッシュが置かれる領域。基本的にこの領域にテーブルやインデックスデータが置かれて、ここを通してデータが返される。一般的にメモリの50〜80%程度をこの領域に使う | インメモリ |
| Log Buffer | ディスク上のログファイルに書き込まれるデータを一時的に保持する領域。redoログにデータをフラッシュする前に、トランザクションがコミットされるまでは個々の領域で保持する | インメモリ |
| Redo Log | INSERT時などのCOMMITタイミングでデータが書き込まれる領域。クラッシュリカバリー時に対応出来るように不揮発性ストレージに書くようになっている | ストレージ |
| Tablesspaces | テーブルやインデックスのデータが置かれている領域 | ストレージ |
| Undo Log | 図には書いてないてないが、トランザクションのロールバックなどの最新の変更を元に戻すときのデータが格納される領域 | ストレージ |
データベースのストレージエンジンの処理の流れとしてはこのような図になっていて、名前はRDBによって違ったりしますが、アーキテクチャの仕組みはどのRDBも基本的に同じになっています。
SELECTの処理のフロー
では実際にSELECTのSQLが発行されたときの処理フローを説明していきます。
SELECTの流れ
- まずデータは基本的にはインメモリのBuffer poolからデータが取り出されるような仕組みになっています。
- Buffer poolにSELECTしたいデータがなかった場合、Tablespacesからデータをフェッチして取得してきます
- その時はディスクを読み込みに行くためI/O負荷がかかることになります
- 一度取得されたデータはBuffer poolの容量が許す限りはキャッシュされます。なので例えば`SELECT * from users where id = 1`というクエリーを一度実行した場合には、次はBuffer poolにデータがあるため、I/O負荷はかからないということになります。
参考
※Buffer poolはLRUアルゴリズムでデータの取捨選択をしています。
ざっくり言うと読み込まれる頻度の高いページは残されて、使用頻度の低いページを削除するアルゴリズムになり、そうすることで効率的にキャッシュを運用しています
(ただ厳密にはMySQLではLRUアルゴリズムではないようです)
※あくまでオーソドックスなフローの説明になるので、その時のCPUやメモリ、各領域の状態によっては上記のようなフローから外れるエッジケースも有るようです
INSERTなどの処理フロー
INSERTの流れ
INESERT INTO users VALUES (1, 'hoge')のようなSQLを実行した場合は想定してみます。- まず基本的にBuffer poolにのデータが書き換えられます(いきなりTablespacesのストレージには書き込みにいかない点は注意です)
- 続いてそのままLog bufferにINSERTしたデータを書き込みます(ここまではインメモリなので高速)
- COMMITが呼ばれたタイミングでLog bufferにあるINSERTしたデータをRead Logに書き込みに行きます(ここで初めて不揮発性のストレージに書き込まれて永続化される事となります)
- 最後にチェックポイントという決まった発生タイミングでTablespacesにINSERTされたデータが書き込まれるというフローになります(チェックポイントのタイミングは様々で、redoログファイルのサイズ分のデータ・ブロック数が書き込まれた時、指定された時間間隔、CPUの負荷が少ない時など様々)
データベース(RDB)の仕組みを理解するとインデックスの貼り方のコツがわかってくる
今回はデータベース(RDB)のアーキテクチャの仕組みについてざっくり説明しました。
プロダクトでパフォーマンスのボトルネックになるのは大体データベースです。
データベースのアーキテクチャや仕組み、インデックスの効率的な貼り方を知っておくと、Webエンジニアとしてのキャリアでも役に立つので、学ぶと良いです!
普段ゆる〜くアーキテクチャやデータベースのことなどを発信しています〜
またMENTAで設計(DDDやクリーンアーキテクチャ)やAWSインフラ、IaC化などを教えていたりしまので、興味のある方は↓からどうぞ!
クラス設計(Clean, DDDなど)をカリキュラムを使って教えます!
サーバサイド&Terraform, CI/CD, AWSインフラの技術サポート
MySQLの仕組みがわかる参考文献
- https://dev.mysql.com/doc/refman/8.0/ja/innodb-architecture.html
- https://dev.mysql.com/doc/refman/8.0/ja/innodb-performance-midpoint_insertion.html
次読むと良い〜バックエンドのやばい設計記事〜